dataproc4:关于复用与遗迹的笔记
“我们在 Lepton 之前,在 R2 之前,在没人拦着我们的时候就搞定了这个。”
> 去 GitHub 上看看 > English Version
[TOC]
📍 为什么要有这个东西
你大概想知道 dataproc4 到底解决了啥问题,以及现在还有啥值得关注的。这篇文章不会带你把每个节点掰开揉碎地讲,而是把核心思路、可复用的设计模式,以及那些已经过时的部分总结一下。 你现在可以直接把整个代码库丢给大模型去分析,这篇文章不是要跟那个抢风头。把它当成一张“意图地图”吧:讲清楚这个系统当初想干啥,而不只是它实际干了啥。
🧱 架构回顾
完整细节请戳 Lark 文档
整个处理流程分了好几个阶段^1^,后面会再聊聊设计的底层逻辑。
-
元数据合并:爬虫 → S3 → 元数据 parquet 文件(*.todo.parquet)
-
预过滤:剔除低质量数据(比如 Pixiv 上 85% 的业余画作)
-
计算指标:通过 SageMaker → *.[metric].parquet
-
指标合并:每个数据集生成一个文件^2^
-
数据集整合:跨数据集对齐图片
-
构建提示词:基于指标过滤 + 提示词生成
-
导出数据集:推送到版本化的 S3 存储桶
flowchart TD
subgraph 来源
Pixiv[Pixiv 原始数据]
Danbooru[Danbooru 原始数据]
Twitter[Twitter 原始数据]
ArtStation[ArtStation 原始数据]
end
UpdateTodos["更新待办<br/>(库存差异 → todo.parquet)"]
SageMaker["SageMaker 任务<br/>(CLIP 分数、softmax、标签器)"]
来源 --> UpdateTodos --> SageMaker
subgraph MergeMeta["元数据合并(工厂)"]
direction LR
clip[CLIP 指标]
tags[机器学习标签]
pixMeta[Pixiv 元数据]
dbrMeta[Danbooru 元数据]
config[数据源配置]
clip --> Core
tags --> Core
pixMeta --> Core
dbrMeta --> Core
config --> Core
Core[基础/Pixiv/Danbooru<br/>合并器]
end
SageMaker --> MergeMeta --> S3Merged["*_merged.parquet → S3"]
Prefilter["预过滤数据<br/>(CLIP 分数 ≥ 1.2、softmax、通用行)"]
S3Merged --> Prefilter
Augment["增强与标签<br/>(像素、年份、质量)"]
Prefilter --> Augment
DedupIntra["去重(数据集内)"]
DedupCross["去重(跨数据集)"]
Augment --> DedupIntra --> DedupCross
Prompt["构建提示词字典<br/>(标题 + 标签)"]
Sanity[" sanity 检查<br/>(AI 标志、艺术家、禁用词)"]
DedupCross --> Prompt --> Sanity
Encode["编码潜变量<br/>(Lepton)"]
Sanity --> Encode --> Training["训练流程"]
Training --> Demo["Gradio / Comfy 演示"]✅ 现在还能用的东西
平台限制变了不少(比如我们现在用 WebDataset + H100s,而不是小内存节点)。很多老的限制已经没了,但当年的设计逻辑依然有价值。
命名空间与逐源合并
dataproc4 处理的是动漫风格的图片,设计时有几个关键假设:
- 同一张图片可能出现在多个平台上
- 标签的质量和可靠性因平台而异(比如 gelbooru 的标签比 danbooru 少)
- 平台有自己的偏见(比如 danbooru 更偏 NSFW)
我们的应对方案是:
- 通过 CLIP 嵌入为图片分配一致的图片 ID,跨平台通用^3^
- 用 {source}__ 前缀合并元数据,避免键冲突
- 按数据源的可信度加权,概率性地合并字段值
这样可以优先选用更可靠的标签,优化提示词结构:关键信息放前面,不确定的放后面,对 CLIP 风格的模型更友好。
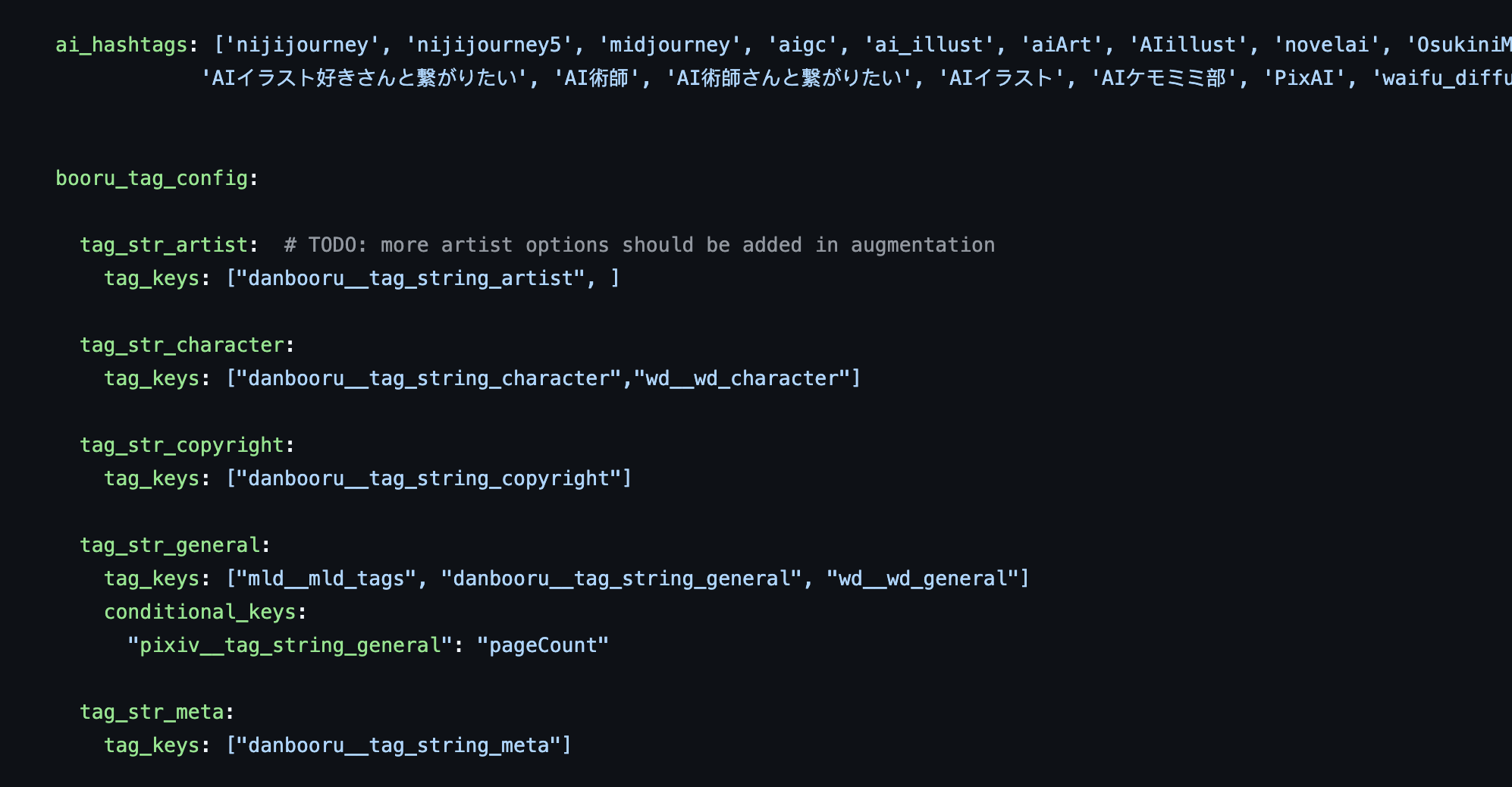
值得一看的代码:pipelines/merge_meta/config.py → 看看流水线配置和 merge_function 如何实现逐源合并。代码链接
确定性流水线
我们用 Kedro 开发,感觉它的理念跟我们的目标挺搭:
- 明确配置 —— 所有输入都在 YAML 文件里定义,绝不硬编码,设计上强制执行^4^
- 流水线优先于步骤 —— 代码围绕端到端流程组织
- 数据即产物 —— 结果来自代码,数据集不是手工打造的
- 确定性优于运行时动态性 —— 没有流水线生成流水线的玩法,可追溯性 > 灵活性^5^
结果就是可复现、清晰、好上手。
(流水线的可变行为都写在配置文件里)
执行模型:检查点 + 可恢复性
dataproc4 的每个阶段都设计成可重启的。检查点让我们可以中途接续工作:
- 中间产物存在版本化的 S3 存储桶里(快又稳)
- 避免手动覆盖数据——流水线生成数据,用户别插手
- 强调以可观察性为先的设计
权衡考量:
| 方法 | 优点 | 缺点 |
|---|---|---|
| S3 版本控制 | 快速、稳定 | 没有预览/UI |
| HF Datasets | 更好用的界面,公开查看器 | 稍慢,但还算靠谱 |
| 本地 parquet | 原型开发快 | 易出错,分享麻烦 |
随着基础设施的进步,检查点逻辑的重要性降低了,但阶段分离依然值得保留——为了稳定性、复用和迭代。
生成标题的流水线里有个缓存中间结果的例子,点这里看看,数据集定义在数据目录里。
原型开发流程
早期的迭代遵循了几个可预测的步骤:
- 用流程图勾勒阶段(我超爱用纸笔)
- 在笔记本里原型化转换逻辑^6^
- 提取稳定代码,变成流水线节点
- 构建完整的 DAG,明确输入输出
这样我们既能快速推进,又不失结构。流水线变得可读、可测、可复现。
别手工打造数据集,别手动改数据,别在笔记本里偷偷搞副作用。流水线是真相的唯一来源,保持它的纯粹。
注意: Cursor 可能不太擅长处理笔记本;用 AI 辅助开发时,笔记本对原型开发还是有用的,但要逐步整合。避免用代理模式改流水线。小修小补很脆弱——先组合、测试,再合并。 在专用测试文件里开发可能是更适合 Cursor 的替代方案。
❌ 哪些部分过时了
内存敏感的分块处理
- 针对 g5.xlarge 的 16GB 内存设计
- 把任务切成小块,避免崩溃
- 强调重试/恢复逻辑和内存上限
现在我们用 8xH100 节点,2TB 内存,分块处理反而成了负担。重试逻辑当年很优雅,但现在可能有点多余。
WebDataset 改造(没做完)
中途发生了结构变化:
- 预训练数据改用 .tar 格式的 WebDataset
- 但 dataproc4 的指标 + 元数据步骤还期望基于路径的输入
- 基于目录的阶段假设悄悄崩了
元数据收集可能需要重写。后半部分的代码可以复用,但得做适配。
深层话题
这篇文档聚焦于复用,有些更深的内容没展开:
- Kedro 项目布局:如何平衡模块化与性能
- 假装声明式的运行时配置 hack
- 数据集下游的训练流水线
- 用 partials + 流水线工厂做 DAG 模板
- 通过 Dask 集群做分布式数据处理
这些得留到另一篇文档——如果有的话。
🏁 总结
dataproc4 真的挺行。
它能扩展,扛得住多人协作,还顶住了各种“敌意”。它对数据混乱的修复——命名规范、概率合并、模块化转换逻辑——至今仍有意义。
复用那些对抗混乱的设计,剩下的就让它自然腐烂吧。
想挖得更深?《第二集》见。
附录
- 没用 Kedro 自带的数据集,我写了 unibox,更快更灵活。
- 为了效率,指标只在一部分数据上计算。
- 去重设置参考 yandere 数据处理文档。
- Kedro 不允许直接传变量,除非记录在配置文件里。不过我们在实际流水线里绕了好几次。
- 八卦一下,Kedro 是咨询公司 McKinsey 开发并开源的。
- 笔记本实验参考 Kedro 的官方文档。
📚 额外阅读
在选定 Kedro 之前,我调研了一堆框架和理念。如果你也在思考流水线策略,或者单纯想看看这个兔子洞有多深,这些链接可能有点用:
数据流水线与 MLOps 通用文章
- Awesome MLOps (kelvins) —— MLOps 生态的精选概览
- 开发可扩展的特征工程 DAG —— DAG 优先的思考
- 工作流编排的演变(视频) —— 回顾编排技术如何变迁
- AI 系统数据转换的分类 —— 转换阶段和边界的清晰拆解
框架对比
- Python 流水线工具包:Airflow、Luigi、Kedro 等 —— 结构权衡的广角概览
- Kedro vs. Hamilton —— 喜欢声明式的可以看看这个对比
- mage-ai/mage-ai —— 界面优先的流水线构建工具
- PrefectHQ/prefect —— 带事件钩子的现代编排工具
- Metaflow + 检查点 —— 运行时优先的设计遇上安全优先的执行
- Kedro + MLflow —— 追踪与可复现性的紧密整合
其他实用工具
- ibis-project/ibis —— 可移植的 Python 数据框层(SQL 抽象)
- posit-dev/great-tables —— 打造整洁的展示表格
- developmentseed/obstore —— 通过 Rust 实现的快速、轻量云存储 IO
- marimo-team/marimo —— 反应式 Python 笔记本,适合 git/版本管理
- 使用 Debezium 和 Python 实现实时数据复制 —— 实时跟踪数据库变化
- deepseek-ai/smallpond —— 基于 DuckDB 的轻量结构化流水线