General Workflow:
Capture Fast, Refine Smart
-
Jot down ideas as they hit—speed over polish—to keep your thought chain alive. Add a quick tag or date for later.
-
Update notes during experiments—log surprises, failures, or pivots as they happen for context.
-
After training, use evolving templates (or LLM prompts) to shape notes into reports.
Workflows Beat Rules
-
Focus on better tools—tweak templates, prompts, or LLM tricks to streamline notes, not enforce note-taking laws.
-
Lean on LLMs to polish, connect, and suggest (e.g., papers, critiques), keeping human effort on the core thinking.
Aesthetics Related:
Current research ideas:
data transforms:
Twitter favorites data is highly unbalanced:
most lies 0-100, but the best ones go above 100k:
import unibox as ub
df = ub.loads("hf://datatmp/data_twitter_fav-normed_full_filtered").to_pandas()
df.describe()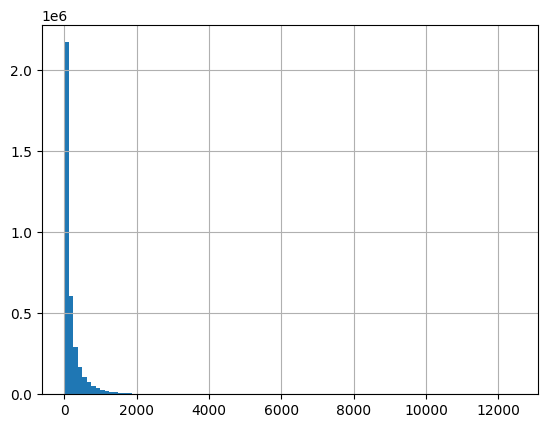 |
Model Archs:
- preliminary tests on small samples shows very simlar results (for convnext vs. vit), if not better
- but on larger dataset of twitter: convnext serires could be harder to adapt to newer tasks (compute inefficient)?
- support: the old (unnormalized version) takes more than a week to train in total (weakm-v3 is 2weeks of 8xH100);
- no way to verify this because there’s severe data leak
- new version (normalized convnext v2-base) took 1.5 days but is still converging slowly.
- support: the old (unnormalized version) takes more than a week to train in total (weakm-v3 is 2weeks of 8xH100);
General training:
Rewarming on the same data may not be necessary, and could harm training progress:
- There’s a paper on rewarming but with LLM but can’t remember where
Green: the initial run
Yellow: subsequent run.
(note that green has a much larger LR than yellow, but usually mse shouldn’t be following exactly the same curve like that).
| Train loss: | Eval MSE: |
|---|---|
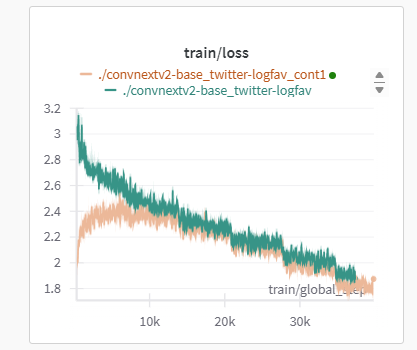 | 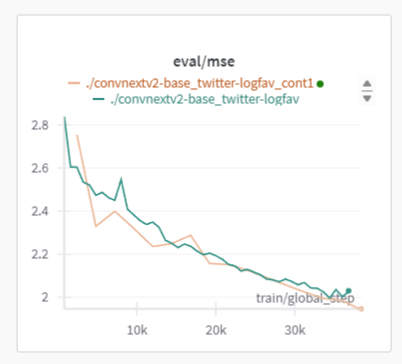 |
| (continuous training has identical mse with orig) | |