dataproc4: Notes on Reuse and Ruins
“we built this before Lepton, before R2, before anyone stopped us.” > view it on github > 中文版
[TOC]
📍 Why This Exists
You want to know what dataproc4 solved—and what still matters. This won’t walk you through every node. It’s a summary of core ideas, re-usable patterns, and what didn’t age well.
You can plug the full codebase into an LLM now. This isn’t competing with that. Think of it as a map of intentions: what the system meant to do, not just what it does.
🧱 Architecture Recap
完整细节请见 Lark文档
The pipeline has several stages ^1^. We’ll revisit the design rationale in later sections.
- Merge meta: Crawler → S3 → metadata parquet (
*.todo.parquet) - Prefiltering: Drop low-quality rows (e.g. 85% of Pixiv is amateur art)
- Calculate metrics: Via SageMaker →
*.[metric].parquet - Merge metrics: One file per dataset ^2^
- Merge datasets: Align images across datasets
- Assemble prompts: Metric-based filtering + prompt building
- Export dataset: Push to versioned S3 bucket
flowchart TD
─────────────────────────────── INGEST & METRICS ────────────────────────────
UpdateTodos["Update Todos<br/>(inventory diff → todo.parquet)"]
SageMaker["SageMaker Jobs<br/>(clip scores, softmax, taggers)"]
Sources --> UpdateTodos --> SageMaker
──────────────────────────────── PREFILTER ────────────────────────────────
Prefilter["Prefilter Data<br/>(clip ≥ 1.2, softmax, general rows)"]
S3Merged --> Prefilter
──────────────────────────────── DEDUPE ────────────────────────────────────
DedupIntra["Dedup (intra‑dataset)"]
DedupCross["Dedup (cross‑dataset)"]
Augment --> DedupIntra --> DedupCross
──────────────────────────────── LATENTS ───────────────────────────────────
Encode["Encode Latent<br/>(Lepton)"]
Sanity --> Encode --> Training["Training Pipeline"]
%% ──────────────────────────────── DEMO ─────────────────────────────────────
Training --> Demo["Gradio / Comfy Demo"]
✅ What’s Still Usable
Platform constraints changed (e.g. we now use WebDataset + H100s, not small RAM nodes). Many old constraints are gone. But the design logic still holds.
Namespacing and Per-Source Merging
Dataproc4 processed anime-style images. Certain assumptions shaped our strategy:
- Same image might appear across multiple platforms
- Tag quality and reliability vary (gelbooru has fewer tags than danbooru)
- Platform bias exists (e.g. danbooru likes NSFW)
We responded by:
- Assigning images a consistent Image ID across sources (via CLIP embedding) ^3^
- Merging metadata using
{source}__prefixes to avoid key collisions - Merging field values probabilistically, weighted by source trust
This let us prioritize more reliable tags, and helped prompt structure: key info up front, uncertain info later, better for CLIP-style models.
Code to Review: pipelines/merge_meta/config.py → See pipeline configs and how merge_function performs per-source merging. source
Deterministic Pipelines
We used Kedro for development. Its philosophy aligned well with our goals:
- Explicit configs — All inputs defined in YAML, not hardcoded, enforced by design ^4^
- Pipelines over steps — Code is grouped around end-to-end flows
- Data as artifact — Results come from code; datasets aren’t handcrafted
- Determinism over runtime dynamism — No pipelines that generate more pipelines; traceability > flexibility ^5^
The result is reproducibility, sanity, and easier onboarding.
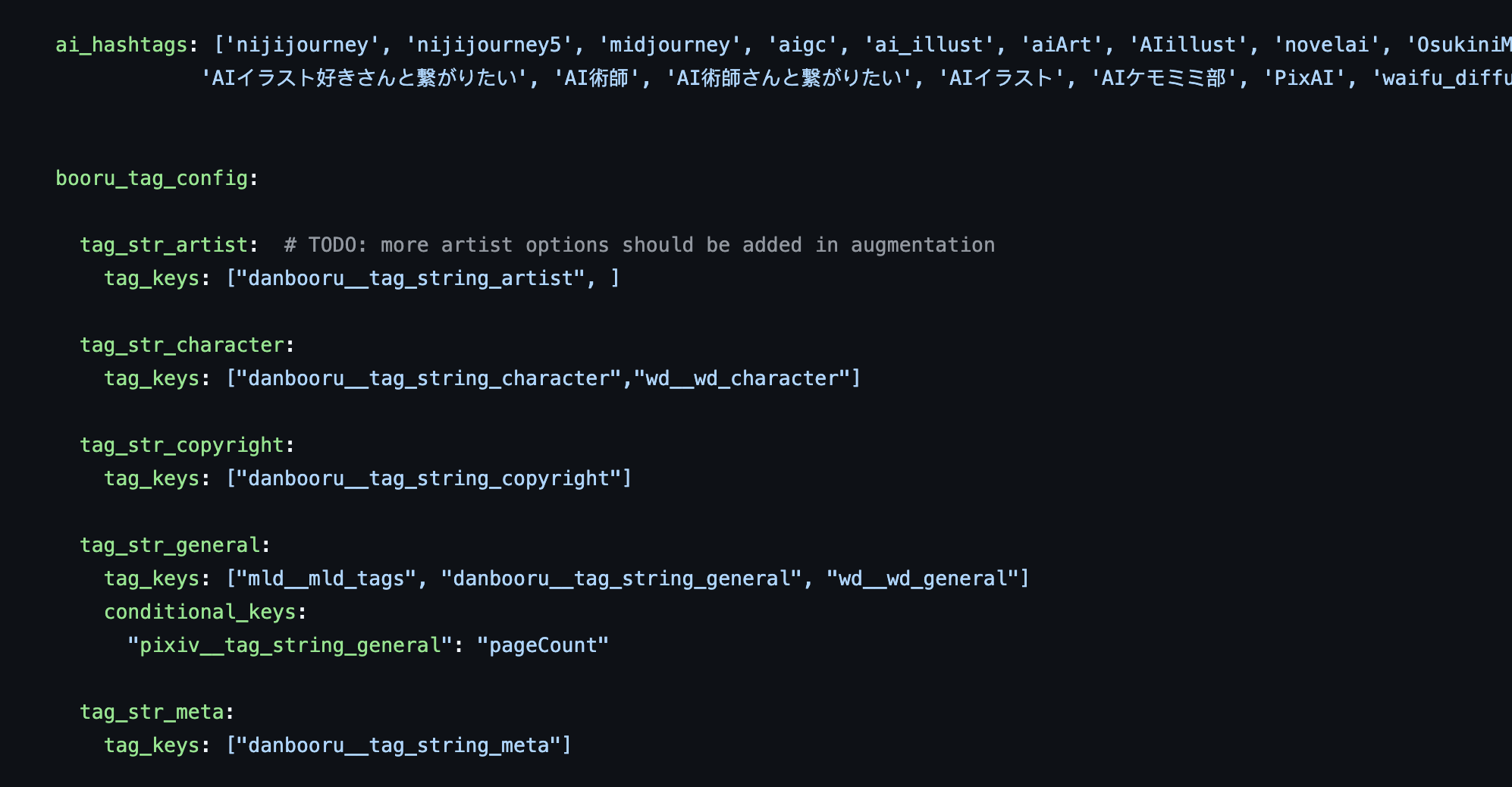
*(Variable pipeline behaviours are encoded into config files).
Execution Model: Checkpointing + Resumability
Each stage in dataproc4 was built to be restartable. Checkpoints allowed us to pick up work midstream:
- Stored intermediate artifacts in versioned S3 buckets (fast, reliable)
- Avoided manual data overwrites—pipelines generate data, not the user
- Emphasized observability-first design
Trade-offs considered:
| Method | Pros | Cons |
|---|---|---|
| S3 versioning | Fast, stable | No preview / UI |
| HF Datasets | Better UX, public viewer | Slower, but sane |
| Local parquet | Fast prototyping | Brittle, hard to share |
Checkpoint logic matters less as infra improves, but stage-separation is still worth maintaining—for stability, reuse, and iteration.
An example of caching intermediate results can be found in the caption-generating pipeline, and the actual dataset is defined in the data catalog.
Prototyping Flow
Early iteration followed predictable steps:
- Sketch stages in a flowchart (I prefer paper a lot)
- Prototype transforms in notebooks ^6^
- Extract stable code → pipeline nodes
- Build full DAGs with clear inputs/outputs
This let us move fast without degrading structure. Pipelines became readable, testable, and reproducible.
Don’t handcraft datasets, don’t mutate data manually, don’t sneak side-effects into notebooks. The pipeline is the source of truth. Let it stay that way.
Note:
Cursor may not handle notebooks well; for AI-assisted dev, notebooks are still useful for prototyping, but integrate gradually. Avoid agent-mode modifications to the pipeline. Small corrections are brittle—compose, test, then merge.
Developing in dedicated test files could be an cursor-friendly alternative to notebooks.
❌ What Didn’t Age Well
Memory-Conscious Chunking
- Designed for
g5.xlargewith 16GB RAM - Chunked work into small pieces to avoid crashes
- Emphasized retry/resume logic and memory ceilings
Now we’re on 8xH100 nodes with 2TB RAM. Chunking adds overhead. The retry logic was elegant, but probably overkill now.
WebDataset Retrofitting (Incomplete)
Structural shift happened midway:
- Pretrain data moved to
.tar-based WebDataset format - But metrics + metadata steps in
dataproc4still expect path-based inputs - Directory-based stage assumptions broke quietly
Gathering meta may need rewrites. The latter parts might be re-used, but only with adaptation.
Beneath the Surface
This document focused on reuse. Some deeper topics weren’t covered:
- Kedro project layout: how we balanced modularity and performance
- Runtime-config hacks that pretended to be declarative
- Training pipelines downstream of datasets
- Use of partials + pipeline factories for DAG templating
- Distributed data processing via Dask clusters
These belong in a separate doc—Episode 2, if you’re brave.
🏁 Final Notes
Dataproc4 worked.
It scaled, handled contributor load, and withstood hostility. Its fixes to data chaos—naming discipline, probabilistic merging, modular transform logic—still matter.
Reuse what fights entropy. Let the rest rot.
If you go deeper, I’ll see you in Episode 2.
Appendix
- Instead of using Kedro’s included datasets, I wrote unibox as a faster and more flexible alternative.
- To increase efficiency, metrics are calculated only on a subset of data.
- Refer to yandere data processing doc for deduplication setups.
- Kedro does not allow passing in variables unless logged inside a config file. Still, we did several bypasses in the actual pipeline.
- Lore wise, Kedro was developed and open-sourced by McKinsey, a consulting firm.
- Refer to Kedro’s official documentation for experimenting with notebooks.
📚 Bonus: Further Readings
Before settling on Kedro, I surveyed a wide field of frameworks and philosophies. These links may be useful if you’re thinking about pipeline strategy—or just want to see how deep the rabbit hole goes:
General Articles on Data Pipelines and MLOps
- Awesome MLOps (kelvins) — A curated overview of the growing MLOps ecosystem
- Developing Scalable Feature Engineering DAGs — Thoughts on DAG-first thinking
- Evolving Workflow Orchestration (video) — Reflects on how orchestration has shifted over time
- A Taxonomy for Data Transformations in AI Systems — Helpful breakdown of transformation stages and boundaries
Frameworks Compared
- Python Pipeline Packages: Airflow, Luigi, Kedro, etc. — Broad overview of structural trade-offs
- Kedro vs. Hamilton — Good side-by-side if you lean declarative
- mage-ai/mage-ai — UI-forward pipeline builder
- PrefectHQ/prefect — Modern take on orchestration with event hooks
- Metaflow + Checkpointing — Runtime-first design meets safety-first execution
- Kedro + MLflow — Tight integration for tracking and reproducibility
Other Useful Tools
- ibis-project/ibis — Portable Python dataframe layer (SQL abstraction)
- posit-dev/great-tables — For building clean display tables
- developmentseed/obstore — Fast, minimal cloud storage IO via Rust
- marimo-team/marimo — Reactive Python notebooks, git/version-friendly
- Real-time Data Replication with Debezium and Python — For tracking database changes live
- deepseek-ai/smallpond — Lightweight, DuckDB-based structured pipelines